In this blog post we will show that open data can effectively shape your customer decisions and give energy to your business, once translated and put into insights; especially in the travel industry, that is ever-changing and deeply related to customer’s commitment.
“There’s no substitute for just going there” wrote Yvon Chouinard, an American climber, environmentalist and businessman who dedicated his life to nature and traveling. A lot has changed since when Yvon traveled around the U.S.A. to climb the Yosemite; technology and internet have radically transformed the travel industry to the point that now holidays find people, not the other way round.
In fact, with the advent of internet and smartphones travelers have been changing their habits and needs, they find all the information they need before, while and after the trip they have been thinking about; this is called Travel 2.0 a travel based extension of the Web 2.0 and refers to the growing presence and influence of the user in the traveling process. Along with the changing of the industry, marketing in the tourism sector is changing just as well and must be revolved around customers, so companies and consultants need to know perfectly their target and who they are talking to.
The core characteristics of tourism activity still remain the same, though:
- tourism is perishable, which is typical of services, as they are consumed while produced so, for example, you won’t be able to sell a room that is vacant today, tomorrow and this is where overbooking comes from;
- tourism is also inconsistent, as the conditions that apply today may not apply tomorrow if it rains the facility may be perceived by customers differently than if it had been sunny and this type of offer can’t be standardized;
- intangibility: how many times have you showed pictures of an hotel room to your friends saying “well, I guess it looked better when I was there” this is because you can’t take home the hotel room in Paris or the view from a chalet in the Alps; tourism is just memories and images depicted in the customer’s mind.
The travel industry is mainly people-oriented, so what better way to develop, for example, an effective campaign than extracting it directly from your customers?
Travelers carry and leave behind a big amount of data: inquiries, questions on forums, bookings, researches about accommodation, transport, itineraries, feedbacks and so on in different stages that go from the idea of getting away to the feedback to the airline company, hospitality structure etc. As a matter of fact, the process that customers face when planning a trip is made of a dizzying number of moments which are rich in intent, even after having booked the trip.
This kind of data is mostly raw and unstructured and comes from different sources but when brought together and analyzed this information will portrait traveler’s behaviors and shape personas from which you can start building a marketing campaign and focus on your target and its needs. Open data have become a tool that can help businesses growing and acquiring new customers when extracted and processed, they can also help to predict the future, giving the hint of a future trend of the business.
In the past few years open data have become a major tool for businesses, they can be leveraged and shaped into solutions deliverable to the final user; along with the growing importance given to open data there has also been a development of free tools, open source softwares and case studies that made having to deal with data easier.
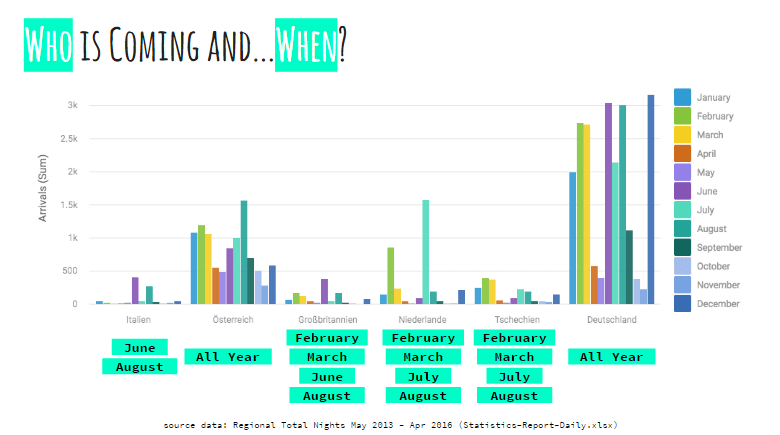
SalzburgerLand, the Salzburg State Board of Tourism, provided us with open data coming from one of their booking channels, it contained information about the flow of visitors in the Salzburg State, for each Nation the table contained the daily amount of Inquiries, Bookings, Arrivals and Nights divided by Country of origin.
We analyzed the data and selected the Nations with the largest amounts of entries which presumably were the ones with the largest tourist flow towards Austria, in this case, Germany, Austria , and Holland.

We were also able to report in which month each of these countries visited Austria, as expected the peak of the tourist flow is reached in the months of February, March and in the Summer (June, July, and August).
Once we came up with these macro-groups we examined their correlations with a pattern of researches on Google and noticed that people looked for Salzburg themed queries in all the moments the table was divided in, moreover analyzing the queries we found out that, for example, German people at the time of booking looked for hotels in specific small towns in the Salzburg area or that Dutch people while they were staying in Salzburg region looked for information about Dolomites, we assumed they were on a trip with a camper van and a research-backed our assumption along with related queries (Camping Italy) that confirmed the intent of continuing the trip driving around Europe. At this point, we had enough information to define the various targets and identify their needs. We created six personas that resembled real people with real needs around which we built the set of queries extracted from the data.
Google published a research on Travel and Hospitality which divided the customer journey in four micro-moments: I-want-to-get-away moments, time-to-make-a-plan moments, let’s-book-it moments, and can’t-wait-to-explore moments. In each one of these moments, customers or potential customers can be taken by the hand and influenced by effective content and campaigns.
Those moments start when people dream of a getaway and go on until they are on holiday, enjoying their fully thought vacation.
We found out that the data we had extracted for our client were highly correlated with relevant patterns of researches on Google, for example, a general query like “ski holiday deals” is more likely searched for during the I-want-to-get-away moment, in which people are browsing and dreaming of their future holiday. The correlation between a query and the researches on Google in a certain Nation can be an opportunity to influence people’s preferences and purchases and to reach customers in all the micro-moments that the trip is made of.

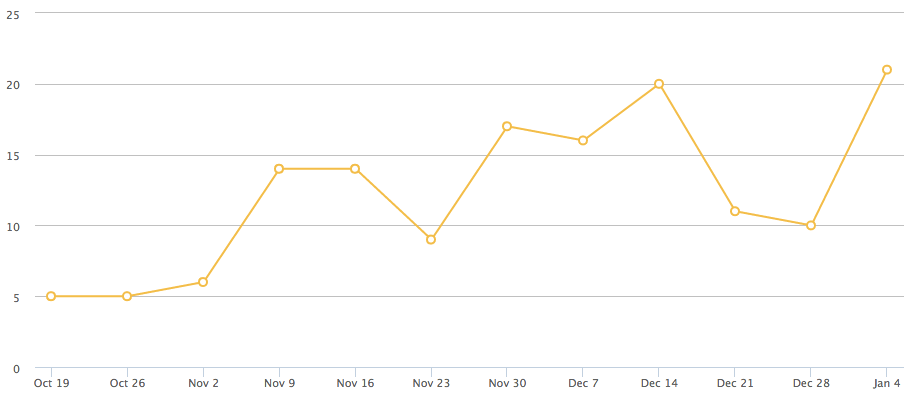
This is Stefan, he is from Germany and he has already been in the Salzburg region so he’s looking for hotels in a specific town and he also wants to know where he can go skiing in Flachau (skigebiet meaning ski area). We also elaborated a graphic of each query’s trend.
This way we can build a content campaign centered on the client’s customers and aimed at conquering and engaging users. We determined what travelers want and when in order to just be there with the right offer.
The creation of the personas worked also as a segmentation based on nationality, travel reason and loyalty so it would be easy to understand the customer’s values and what to create. The aim of marketing and content marketing, in the age of smartphones, is to connect to the person you want to reach out and deliver the answers they are looking for, be relevant to the user when in need and be on time.
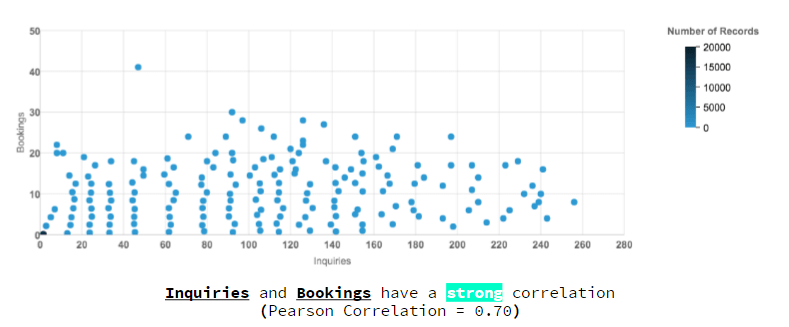
When examining the data we discovered that Inquiries drive Bookings because the two are strongly correlated (Pearson Correlation=0.70) as we expected, so we could predict the trend of the bookings in the future, as the graphic below shows and this data can be useful to programme and deliver campaigns on time to users.
A data-backed marketing campaign can fuel your business growth centering it around your customers and adapting it to the modern standards of connectivity and sharing; we can transform plain data and grey spreadsheets into beautiful, compelling stories that will draw your target’s attention.
In the end, all will be at hand, even the Yosemite, at least online!
Find out more on how this analysis has helped SLT, after the first 6 months, outperforming the competition by bringing 92.65% more users via organic search than all other travel websites in Austria (from the WordLift website)!






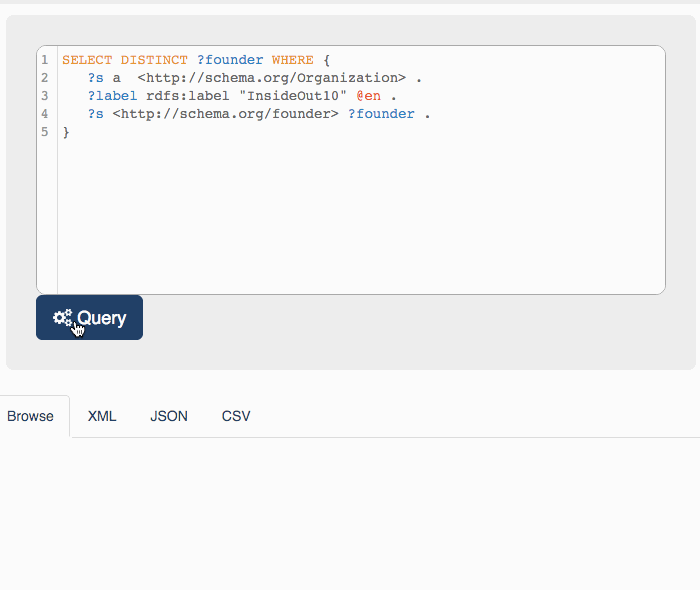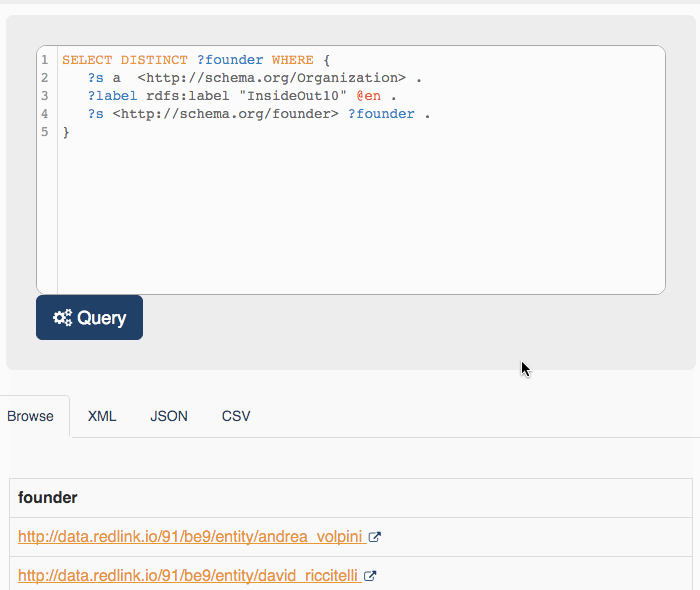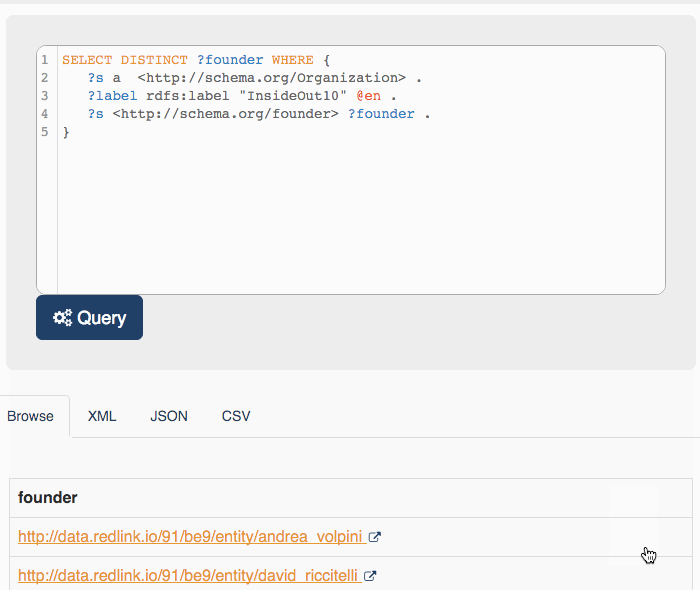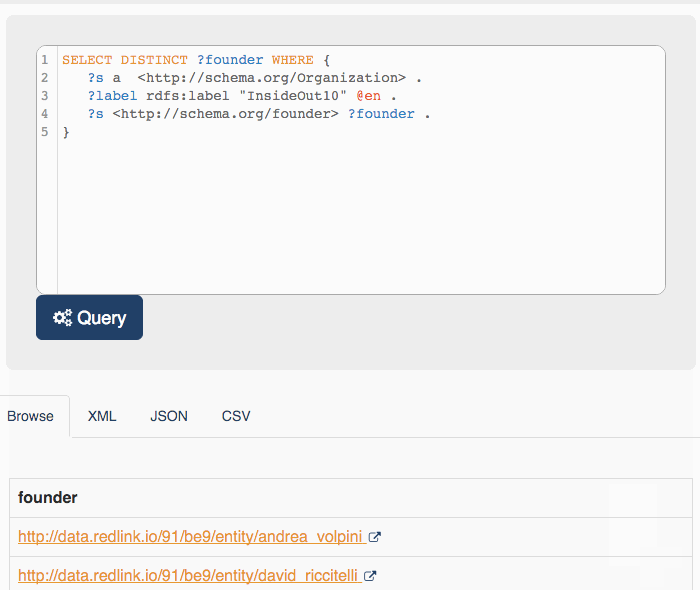














 Understanding that WordLift, and the go-to-market process that will follow shall be
Understanding that WordLift, and the go-to-market process that will follow shall be