The blog post summaries the work done in the context of the EU project FP7-MICO in the area of digital journalism.
This last December we attended in Cairo one of the most exciting events in the Middle East and North Africa region on Entrepreneurship and Hi-Tech startups: RiseUp Summit 2015. We engaged with the overwhelming crowd of startuppers and geeks on our HelixWare booth and in a separated Meetup organised at the Greek Campus.
We had the opportunity, during these two hectic days, to share the research work done in MICO for extending the publishing workflows of independent news organizations with cross-media analysis, natural language processing and linked data querying tools.
When we first started WordLift, we envisioned a simple way for people to structure their content using Semantic Fingerprinting and named entities. Over the last few weeks we’ve seen the Vocabulary as the central place to manage all named entities on a website. Moreover we’ve started to see named entities playing an important role in making the site more visibile to both humans and bots (mainly search engines at this stage).
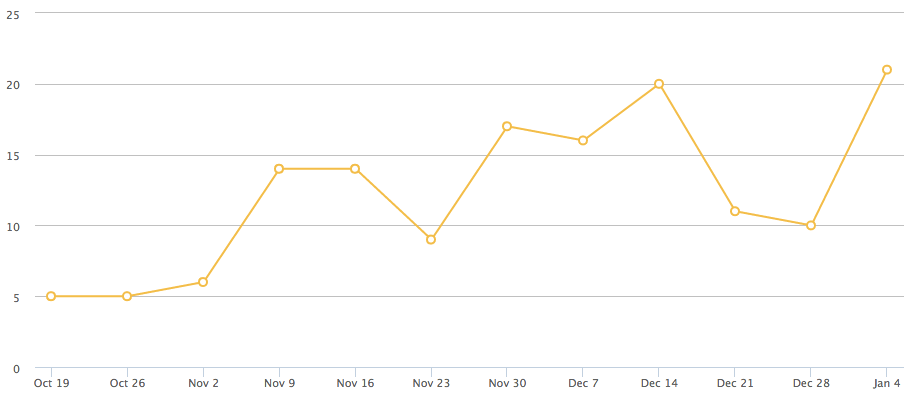
Here is an overview on the numbers of weekly organic search visits from Google on this blog (while numbers are still small we’ve a 110% growth).
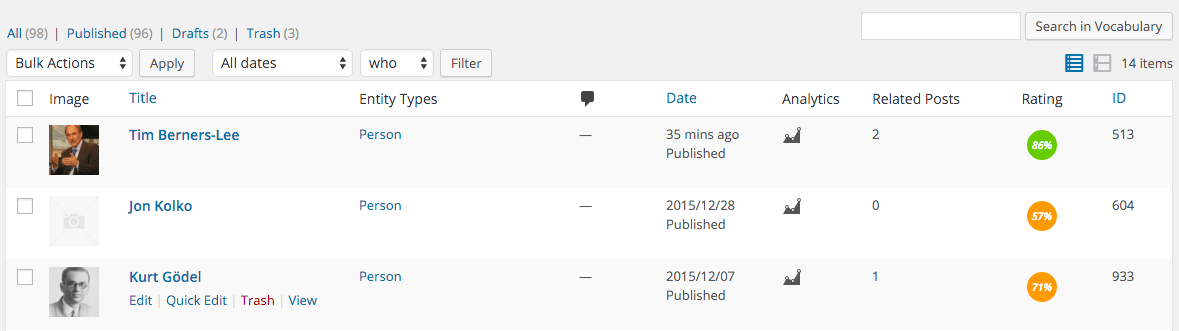
To help editors increase the quality of their entity pages, today, we are launching our new Vocabulary along with version 3.3.
The Vocabulary can be used as a directory for entities. Entities can now be filtered using the “Who“, “Where“, “When” and “What” categories and most importantly entities have a rating and a traffic light to quickly see where to start improving.
Until now it was hard to have a clear overview (thumbnails have been also introduced); it was also hard to see what was missing and..where. The principles for creating successful entity pagescan be summarised as follow:
Every entity should be linked to one or more related posts. Every entity has a corresponding web page. This web page acts as a content hub (here is what we have to say about AI on this blog for example) – this means that we shall always have articles linked to our entities. This is not a strict rule though as we might also use the entity pages to build our website (rather than to organise our blog posts).
Every entity should have its own description. And this description shall express the editor’s own vision on a given topic.
Every entity should link to other entities. When we chose other entities to enrich the description of an entity we create relationships within our knowledge graph and these relationships are precious and can be used in many different ways (the entity on AI on this blog is connected for instance with the entity John McCarthy who was the first to coin the term in 1955)
Entities, just like any post in WordPress, can be kept as draft. Only when we publish them they become available in the analysis and we can use them to classify our contents.
Images are worth thousand words as someone used to say. When we add a featured image to an entity we’re also adding the schema-org:image attribute to the entity.
Every entity (unless you’re creating something completely new) should be interlinked with the same entity on at least one other dataset. This is called data interlinking and can be done by adding a link to the equivalent entity using the sameAs attribute (here we have for instance the same John McCarthy in the Yago Knowledge Base).
Every entity has a type (i.e. Person, Place, Organization, …) and every type has its own set of properties. Whenwe complete all the properties of an entity we increase its visibility.