How more context can help us revamp HelixWare’s Video player to boost user engagement on news sites.
originally posted on http://www.mico-project.eu/reimagining-the-video-player/
Our use case in MICO is focused on news and media organisations willing to offer more context and better navigation to users who visit their news outlets. A well-known (in the media industry at least) report from Cisco that came out this last February predicts that nearly three-fourths (75 percent) of the world’s mobile data traffic will be attributed to video by 2020.

The latest video content meetup – organized in Cairo this March with the Helixware’s team at Injaz. (Images courtesy of Insideout Today)
While working with our fellow bloggers and editorial teams we’ve been studying how these news organizations, particularly those with text at their core, can be helped in crafting their stories with high-quality videos.
More over, the question we want to answer is: can videos become a pathway to deeper engagement?
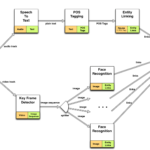
With the help of MICO’s media extractors we can add semantic annotations to videos on demand . These annotations are in the form of media fragments that can be used as input for both the embeddable video player of HelixWare and the video thumbnails created by HelixWare WordPress plugin. Media fragments, in our showcase, are generated from the face detection extractor and are both temporal (there is a face at this time in the video) and spatial (the face within these frames is located at xywh).
The new HelixWare video player that we’re developing as part of our effort in MICO aims at creating an immersive experience for the end-users. The validation of both video player and video thumbnail will be done using A/B testing against a set of metrics our publishers are focused on: time per session, numbers of videos played per session, number of shares of the videos over social media (content virality).
Now let’s review the design assumptions we’ve worked on so far to reimagine the video player and in the next post we will present the first results.
1. Use faces to connect with users
Thumbnails, when done right, are generally key to ensuring a high level of engagement on web pages. This seems to be particularly true when thumbnails feature human faces that are considered “powerful channels of non-verbal communication” in social networks. With MICO we can now offer to the editor a better tool to engage audiences by integrating a new set of UI elements that use human faces in the video thumbnail. The study documenting this point is “Faces Engage Us: Photos with Faces Attract More Likes and Comments on Instagram” and has been authored by S Bakhshi, D. A. Shamma, E. Gilber in 2014.
2. Increase the saturation by 20%-30% to boost engagement
Another interesting finding backing up our work is that filtered photos are 21% more likely to be viewed and 45% more likely to be commented on by consumers of photographs. Specifically, filters that increase warmth, exposure and contrast boost engagement the most.
3. Repeat text elements
As seen in most of the custom thumbnail tutorials for YouTube available on-line adding some elements of the title or the entire title using a bold font over a clear background can make the video more compelling and accordingly to some, significantly increase the click-through-rate. One of the goals of the demo will be to provide a simple and appealing UI where text and image cooperate to offer a more engaging user experience removing any external informations that could distract the viewer.
4. Always keep the editor in full control
We firmly believe machines will help journalists and bloggers focus on what matters most – writing stories that people want to read. This means that whatever workflow we plan to implement there shall always be a human (the editor himself) behind the scene validating the content produced by technologies such as MICO.
This is particularly true when dealing with sensitive materials such as human faces depicted in videos. There might be obvious privacy concerns for which an editor might choose to use a landscape rather than a face for his video thumbnail and we shall make sure this option always remains available.
We will continue documenting this work in the next blog post and as usual we look forward to hearing your thoughts and ideas – please email us anytime.


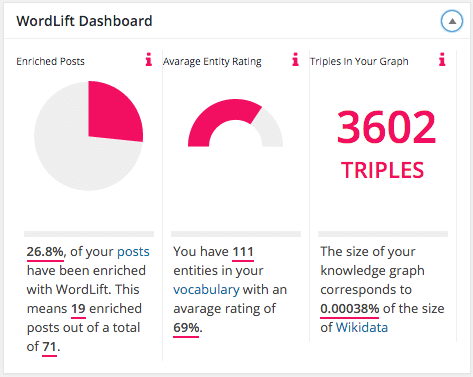
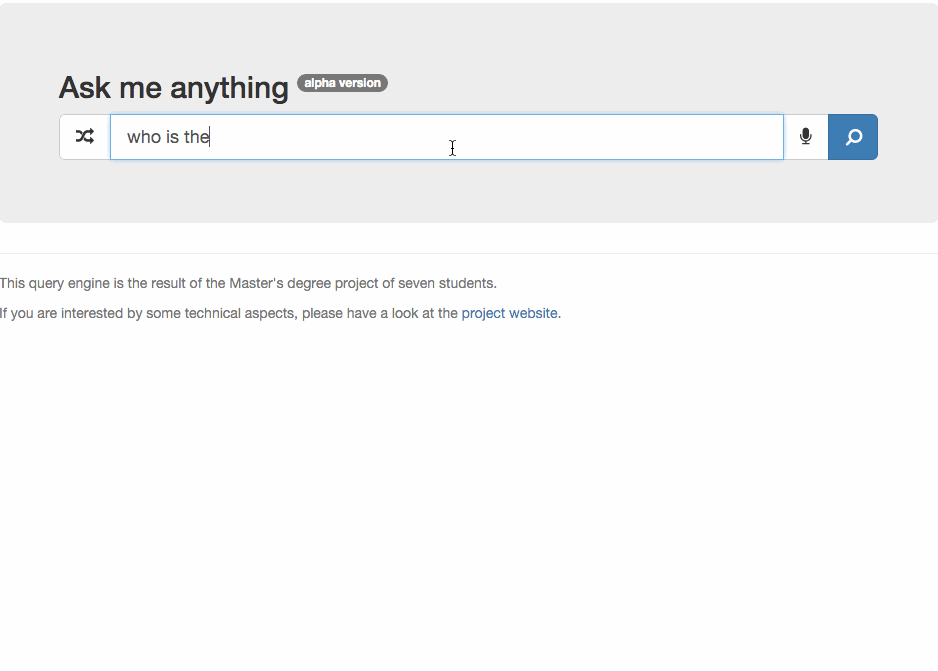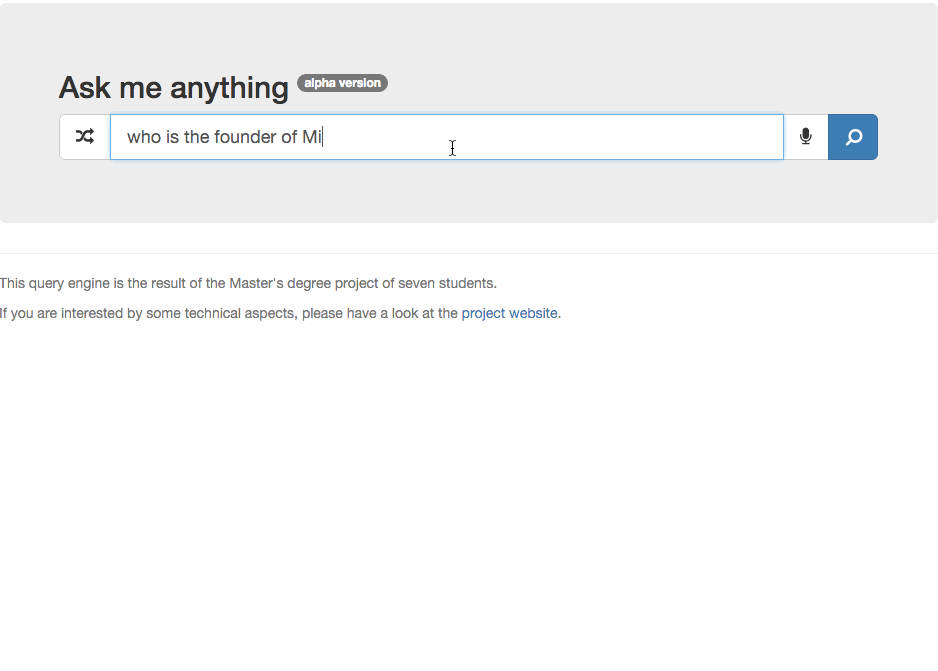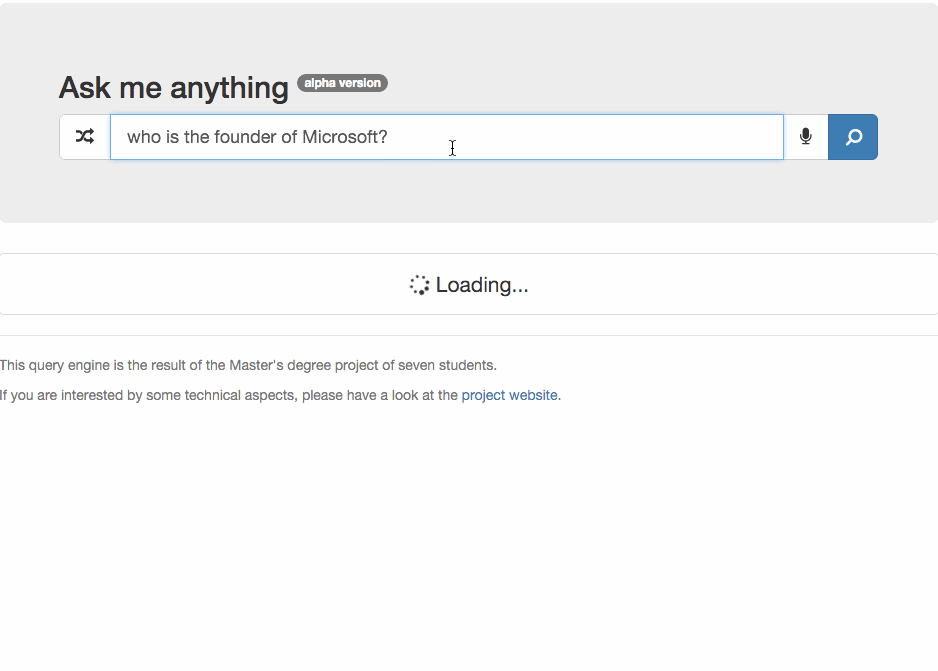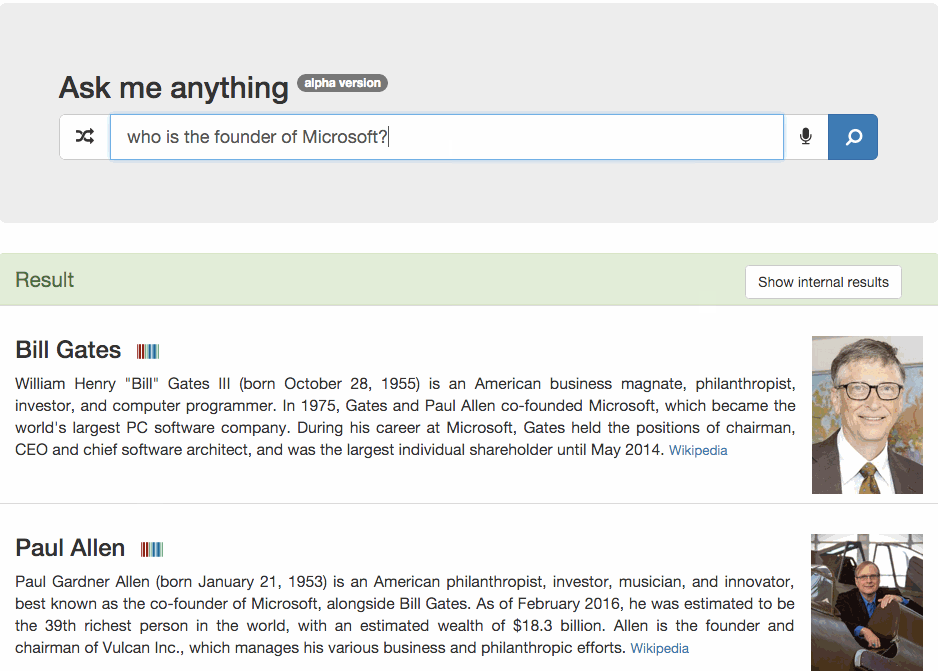







 Understanding that WordLift, and the go-to-market process that will follow shall be
Understanding that WordLift, and the go-to-market process that will follow shall be