


Questo post racconta il making of di una startup e il “dietro le quinte” dello sviluppo di un prodotto innovativo.
Sviluppare insieme attorno ad uno stesso tavolo un prodotto come WordLift in questa fase (a qualche mese dal rilascio ufficiale) è un po’ come ritrovarsi in un piccolo café di fine ottocento a Parigi. L’atmosfera, in apparenza rilassata, è figlia di un tempo segnato ormai irreversibilmente dal rapido processo di sviluppo industriale avviatosi…a Parigi nel XVIII secolo e, lo scorso Agosto tra le montagne dell’Abruzzo nel caso di WordLift. Senza spingermi ulteriormente sul parallelismo vediamo velocemente da dove siamo partiti e cosa abbiamo realizzato.
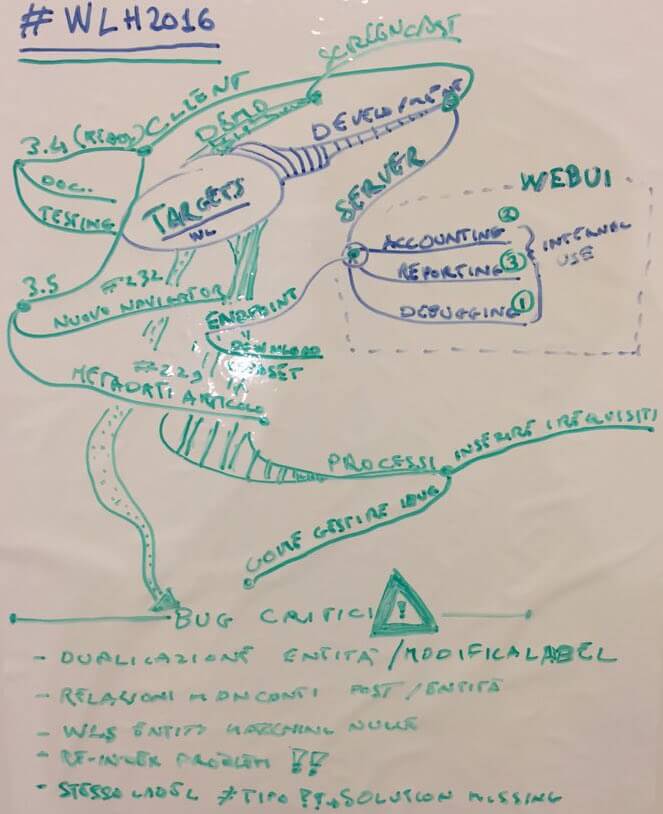 Le sfide principali in questa fase del lavoro coinvolgono quattro ambiti:
Le sfide principali in questa fase del lavoro coinvolgono quattro ambiti:
- Lo sviluppo del software – l’obiettivo è semplice: abbiamo un insieme ben definito di funzionalità da traguardare per la versione che sarà messa sul mercato e dobbiamo risolvere tutti i malfunzionamenti che stanno emergendo dalla fase di test.
- La validazione con gli utenti – in questo ambito si tratta di lavorare in un costante one-to-one con i nostri dedicatissimi beta-tester con il duplice obiettivo di valorizzare il loro utilizzo di WordLift e di acquisire tutte quelle informazioni che ci possono aiutare a prioritizzare le attività di sviluppo.
- La definizione della strategia di go-to-market – i prodotti innovativi hanno una complessità intrinseca che è legata alla difficoltà di comunicare ai potenziali clienti qual è il bisogno a cui il prodotto risponde. Lavorare sul go-to-market significa definire una strategia per il lancio che sia efficace per un vasto numero di tipologie di utenti.
- La definizione dei processi di lavoro – qui si tratta di capire se ed in che modo le attuali modalità di svolgimento del lavoro sono efficaci e se ci sono dei margini di miglioramento. All’inizio, su tanti fronti si procede per tentativi, misurazioni ed iterazioni successive (lean insegna…almeno parte) ma via via il tutto dovrà essere razionalizzato per consentire al team di gestire un numero crescente di utenti.
Ora vediamo cosa abbiamo raggiunto su questi quattro fronti:
Sviluppo
Nel corso dell’hackathon abbiamo lavorato su una serie di bug che ci consentiranno questa settimana di pubblicare la versione 3.4 di WordLift (hurrah!). La nuova versione introduce il nuovo faceted search widget. Questo widget consente di filtrare tutti i contenuti associati ad una determinata entità attraverso la rete delle entità collegate ai diversi articoli: vediamolo in azione in questo articolo.
Le entità sono ora organizzate secondo il criterio delle 4W ed è chiaro – a partire da questo esempio – che le entità dovranno essere ridotte in numero ed ordinate per importanza per evitare che il widget risulti troppo invasivo.
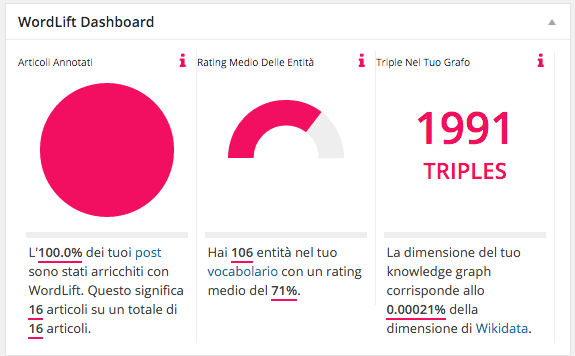 Sempre sul fronte dello sviluppo è in arrivo la prima dashboard di WordLift che ci aiuta a scoprire immediatamente le dimensioni del grafo di conoscenza del nostro sito.
Sempre sul fronte dello sviluppo è in arrivo la prima dashboard di WordLift che ci aiuta a scoprire immediatamente le dimensioni del grafo di conoscenza del nostro sito.
In particolare le informazioni che troverete nella bacheca di WordPress sono le seguenti:
- Numero degli articoli annotati con WordLift,
- Rating medio delle entità (ovvero la qualità delle entità che abbiamo all’interno del nostro vocabolario)
- Numero di triple (ovvero tutte le asserzioni – o fatti – formate da soggetto, predicato e valore) che caratterizzano il grafo di conoscenza che stiamo creando con WordLift.
Validazione
Nella validazione con gli utenti abbiamo avuto il piacere di lavorare con alcuni di loro e, almeno secondo quanto condiviso in questi giorni, ci siamo resi conto che dobbiamo migliorare le funzionalità di visualizzazione e selezione dati del navigator widget. Si tratta di un componente centrale per consentire ai blogger di introdurre in pagina collegamenti con altri articoli che siano al tempo stesso rilevanti e contestualizzati. Il lavoro è su questo fronte già iniziato.
How shall the new navigator widget look like? Can we boost your contents with a revamped user experience? You bet! pic.twitter.com/ljTwobZfpP
— WordLift (@wordliftit) February 6, 2016
Go-to-market
Dobbiamo lavorare attentamente nei mesi che verranno per:
- fare del nostro meglio per fornire agli utenti ciò che è per loro più importante rispetto all’organizzazione dei contenuti che pubblicano sui propri siti
- comunicare WordLift nel modo più efficace possibile in modo che tutti sappiamo cosa effettivamente stanno cercando dal nostro prodotto
Esiste in questo senso una dialettica molto stringente che lega la roadmap (ovvero quali feature supportare e in che modo) con la comunicazione e il marketing.
Nel caso di WordLift, come per qualunque altro prodotto innovativo, non abbiamo un mercato definito dove è sufficiente adattare il prodotto per raggiungere il migliore compromesso per l’utente: dobbiamo adattare ed incidere sull’intero mercato di riferimento.
Il fatto che i contenuti che produciamo si possano perdere nel mare magnum della comunicazione globale è chiaro a tutti. L’idea che organizzando la nostra conoscenza possiamo risolvere il problema alla radice non è invece affatto scontato.
Siamo abituati a piattaforme e servizi estremamente complessi offerti dai colossi del Web in forma gratuita e l’idea che queste stesse tecnologie possano entrare nel nostro blog è difficile da trasmettere. E’ inoltre evidente che l’unico modo efficace per misurare il successo di WordLift è legato alla capacità di modificare realmente il comportamento di chi lo usa.
Quando abbiamo scoperto, lavorando con Greenpeace Italia, che utilizzando WordLift la redazione ha iniziato ad acquisire una nuova forma di auto-consapevolezza rispetto ai propri contenuti abbiamo capito che ci muoviamo nella giusta direzione (qui un articolo uscito sul magazine della Commissione Europea CORDIS che parla di questi primi risultati).
Processi
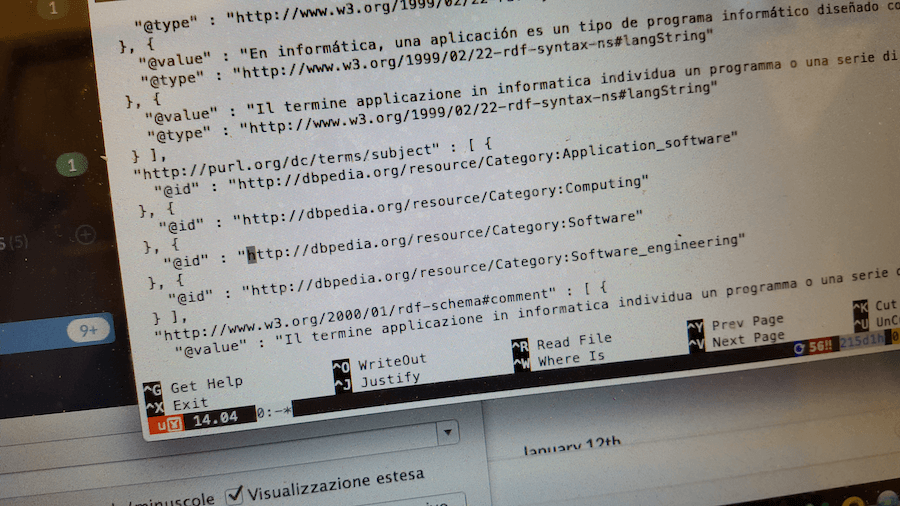
Un primo passo su questo fronte l’abbiamo fatto durante l’hackathon rendendo più accessibili i dati del backend di WordLift al team di sviluppo e supporto. In questo modo possiamo analizzare eventuali problemi relativi all’analisi del testo (la parte indubbiamente più complessa del prodotto) risparmiando tempo e energia.
Il primo hackathon del 2016 si è tenuto a Roma nel “grottino” di InsideOut10.
WordLift è il software utilizzato su questo blog per organizzare e promuovere i contenuti.
















 Come startup che lavora in questo settore, siamo a nostra volta “clienti” della soluzione, questo costituisce un punto di vantaggio e un
Come startup che lavora in questo settore, siamo a nostra volta “clienti” della soluzione, questo costituisce un punto di vantaggio e un 



