


Come un post può cambiare l’opinione generale dell’intera Europa (in questo caso l’Unicef aveva parlato dell’importanza dei vaccini)
La tecnologia semantica organizza i contenuti secondo strutture ontologiche condivise, identifica: concetti, relazioni e proprietà. Tutti i siti e i Blog generici o tematici, che da anni dominano anche il mondo dell’informazione professionale, non sono supportati da applicazioni che costruiscono archivi strutturati associando metadati in automatico al momento della pubblicazione. Il risultato è un mare di ‘contenuti momentanei’, postati con linguaggi di gestione legacy, organizzati in forme che richiedono l’intervento delle tecniche di ‘conversione’ dei dati e di attività di marketing digitale, per essere diffuse e trovate dall’utente, anche se per un breve arco di tempo.
Nei dieci anni dalla prima diffusione di internet siamo passati da una fase in cui collegavamo i computer, alla successiva in cui abbiamo linkato le pagine, a quella di oggi che ci chiede di collegare i dati. Il web deve essere in grado di riconoscere il significato dei dati e delle parole pubblicate.
Nel settembre del 2014 internet ha superato il miliardo di siti e nell’estate del 2013 già si contavano 100 miliardi di click al giorno, 55 migliaia di miliardi di link tra tutte le pagine web del mondo. Viene da sé che l’importanza primaria è quella di programmare non solo l’organizzazione dei contenuti pubblicati in un sito in temi, canali e layout classici, ma riprogettare gli stessi perché costruiscano dataset arricchiti di metadati, meglio se fatto secondo le specifiche del W3C per permettere l’integrazione con la cloud Linked Open Data.
Inoltre, gli ‘oggetti tecnologici’ che ci permettono di comunicare e svolgere attività on line non sono più meri ‘strumenti’: sono diventati oramai veri e propri ‘dispositivi culturali’. Sono in grado di evidenziare l’essenza della persona, del posto (luoghi, o territori), delle Organizzazioni di cui fanno parte: private o pubbliche.
I dispositivi danno un significato espresso in dati a contesti informali come lo sono i network, che assumono sempre più una struttura in grado di esprimere la dimensione identitaria e culturale sia del gruppo che del singolo. Possiamo affermare che la nostra vita si snodi in una dialettica di sviluppo che ha sullo sfondo una sequenza di contesti ‘digitali’.
L’insieme di questi contesti e delle funzioni cui questi obbediscono, rispecchia la quotidianità delle forme di vita che in essa si sviluppano, e quindi anche delle direzioni delle traiettorie di sviluppo, e dei metodi di comunicazione usati per condividerla.
I siti internet devono tener in debito conto delle potenzialità espressive e delle modalità d’uso dei dispositivi collegati alle reti digitali. Alcuni usi sono già consolidati, e non solo tra i target giovanili e la ‘generazione touch-screen’.
Nel 2011 abbiamo iniziato lo sviluppo di un Editor Semantico, WordLift, oggi fine ottobre 2015 alla terza release. L’applicazione è distribuita come Plug-in in una delle piattaforme di CMS open source più diffuse al mondo: WordPress. Il modulo è già disponibile su Alfresco e in versione sperimentale su Drupal – è in calendario lo sviluppo dei connettori verso altri CMS.
L’Editor Semantico WordLift 3.0 è sviluppato e automatizzato per consentire la costruzione di dataset open secondo gli standard richiesti dal W3C. Il software suggerisce all’utente già in fase di compilazione di un articolo: le entità, i concetti e le relazioni che classificano il contenuto con le chiavi di lettura presenti negli archivi open data: dbpedia, freebase, geonames, i più famosi.
Questo fa si che le informazioni siano accessibili sotto forma di grafo semantico (i contenuti testuali diventano dei dati e possono essere così letti dalle macchine e collegati con altri dati).
Il prodotto WordLift 3.0 è in grado di recepire “programmi di verticalizzazione” e predisporre la configurazione dell’arricchimento dei contenuti con i dati necessari al riuso, cioè a rispondere alle richieste di servizio provenienti da applicazioni web esterne, applicazioni per mobile e API.
Se, ad esempio, prendiamo in considerazione l’eventualità di realizzare un sito dedicato agli open data di una Istituzione europea ci poniamo come obiettivo quello di sviluppare una verticalizzazione di WordLift 3.0 con un Dominio Informativo ad hoc e l’inserimento di tutti i vocabolari del settore Pubblico disponibili (es. Eurovoc, Core Public Service, Core Business Vocabulary, DCAT, …), e di ontologie già affermate e/o nuovi standard (criteri o indicatori di performance).
Pubblicare i contenuti sul web usando l’editor semantico WordLift 3.0 vuol dire per tutta l’utenza WordPress organizzare il proprio desk e costruire un archivio strutturato dei propri contenuti compatibile con la cloud Linked Open Data senza ostacolare l’eventuale uso di Licenze commerciali per la distribuzione dei contenuti.













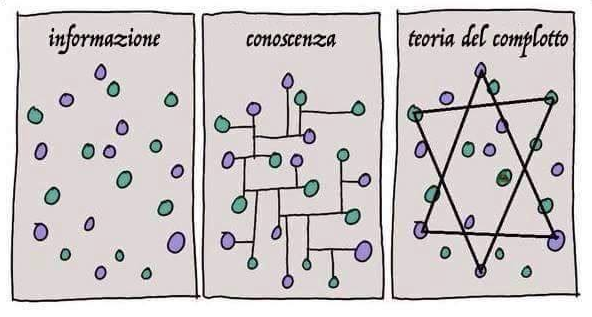 WordLIft 3.0 fa passare dall’informazione alla conoscenza evitando il complotto.
WordLIft 3.0 fa passare dall’informazione alla conoscenza evitando il complotto.