Al festival internazionale del giornalismo, aprile 2015, si è discusso del giornalismo digitale e della difficoltà a trovare un nuovo modello che permetta al giornalismo di essere pagato, e quindi sopravvivere.
Zero Calcare invitato al festival perchè con le striscie pubblicate su internazionale.it è stato in grado di coinvolgere i più giovani.
Anche uno scrittore che più influenza i pensieri degli americani riguardo al rapporto con i new media, Jonathan Franzen, ma non ho letto niente di Lui, dice che si ritiene fortunato perchè in quanto romanziere è pagato per i contenuti che produce; mentre chi lavora nel web fa fatica soprattutto se è un freelance.
A dirla tutta ha cattive opinioni sui nuovi tipi di professione di informatori digitali, perché: disinformano, opprimono e uniformano le opinioni. E si riferisce rispettivamente ai: leakers, citizen journalist, crowd sourcing, che danno solo opinioni personali e a volte violente.
Nel web ci sta tutto e personalmente diffido di chi addita come derive le “prove tecniche” sulle potenziali nuove professioni che da 20 anni circa vengono promosse dalla tecnologia, o domandano tecnologie per esprimersi. Sembrano come lamenti di una gioventù passata.
Nel corso del festival del giornalismo digitale un giornalista del Guardian, Aron Pilhofer, in un intervento illustra la loro esperienza, che ha dato come risultati alcune attività necessarie al ridisegno della professione di giornalista. Non si tratta solo di possibili risposte a domande tipo: quale potrebbe essere il nuovo business? come monetizzare, o quale è il valore economico della relazione con i propri lettori? Ma si parla della necessità di “ordinare la redazione”, “nuovo desk”, “live desk”, “visual desk”, e organizzare in: business, national, international la base del loro approccio al mercato.
Il dispositivo di lettura informazioni non è più cartaceo come si evince dalla vecchietta nella foto che segue.
Se si parla di circa 200mila quotidiani al giorno .. on line sono 120milioni (fonte The Guardian), abbiamo una stima dell’offerta di contenuti, ma anche della necessità di riordinare le redazioni digitali al fine di costruire i propri archivi interni in relazione ai temi trattati dalla testata, e che gli stessi siano conformi agli archivi open sul modello dbpedia di internet.
Dobbiamo allo stesso tempo ridare forza alla professione del giornalista dotando la redazione di strumenti in grado di supportare sia la fase di scrittura, che quella di pubblicazione dei contenuti senza richiedere skill tecnici al giornalista digitale. Proprio come auspicato dal compianto da poco David Carr del New York Times.
Ci sono anche gli altri orientamenti, dipende dove ti metti e verso cosa guardi. Io Maurizio sono nato e vivo in Italia e se devo raccontare della mia specie …: è reale dire che sono figlio di una combinazione infinita di casualità. Già! Solo a pensare alla difficoltà di incontro dei genitori negli anni ‘50, comprendo che per nascere dovevo avere una grande esperienza, anche estetica; una conoscenza appropriata del marketing analogico, soprattutto nei meccanismi di verifica dell’idea o della fattibilità tecnica; dovevo aver definito gli obiettivi, organizzato gli appuntamenti importanti, etc.. Non so in che percentuale abbia immaginato la vita, ma questo dipende da quanto mi sono applicato, se ero al bar o più semplicemente dormivo.
Poi sono nato e l’aria ha scombinato tutto. Non c’è più memoria e la vita risponde: vabbè rifacciamola. Molti anni dopo ho le stesse domande di tutti, un elenco abbastanza corposo, in cima possiamo mettere tranquillamente:chi sono?
In Occidente e comunque verso sud, forse in Perù ad essere precisi, Condori disse a Kantu: se vuoi convertire i tuoi sogni in realtà devi imparare a conoscere te stessa… e cosa devo fare? .. trovare risposte … e le domande iniziano sempre con quella in cima anche al mio elenco.
Ma torniamo a WordLift 3.0, che è un’editor semantico ad uso degli utilizzatori della piattaforma di CMS WordPress: come fa ad essere uno strumento utile a descrivere alle macchine un contenuto metaforico?
Non lo so ancora, bisognerà provare più e tante storie. Ma intanto, per costruire dataset open sugli antichi saperi orientali, sulle corrispondenze tra mente e corpo, e compararli con altrettanti costruiti su nuove scienze come la neurobiologia: è perfetto!
Verso la seconda metà di Marzo di quest’anno abbiamo per la prima volta iniziato a ragionare sull’ipotesi di dare un contributo per rivedere le funzionalità e l’organizzazione del catalogo nazionale degli Open Data Italiani. Questo articolo vuole essere il diario di bordo di quanto svolto sul nuovo dati.gov.it in termini di design dell’informazione e implementazione tecnologica.
Ci occupiamo, come Insideout10, di open data e linked open data da diversi anni e abbiamo colto la sfida di AgID di ereditare il lavoro svolto dal Formez e da Sciamlab a partire dal 2011 sul catalogodati.gov.it.
Architettura dell’informazione
Partendo dalla richiesta iniziale di rendere i dataset quanto più accessibili e fruibili ai target di utenza primari identificati dall’Agenzia (cittadini, imprese, professionisti e pubblica amministrazione), il lavoro iniziale è stato quello di analizzare il contesto di riferimento e le modalità di accesso consolidate tra le diverse tipologie di utenza.
[slideshow_deploy id=’266′]
Lo svolgimento di questa parte di analisi lo abbiamo condotto abbinando tecniche miste di analisi dei dati, definizione delle personas, studio dei casi di successo (eh si dobbiamo anche qui ammettere di esserci deliberatamente ispirati al portale degli open data Indiano e da quello Africano invece che rifarci ai più blasonatidata.gov.uk edata.gov) e comune buon senso.
Come startup che lavora in questo settore, siamo a nostra volta “clienti” della soluzione, questo costituisce un punto di vantaggio e un bias da tener sotto controllo. In pratica siamo partiti dal .csv contenente la lista di tutti i dataset presenti originariamente nel catalogo e abbiamo iniziato a visualizzare la struttura dei dati usando una nostra versione personalizzata di RAW(un utilissimo tool di visualizzazione realizzato dal Politecnico di Torino che abbiamo integrato con alcune visualizzazioni provenienti da D3.js per leggere le informazioni aggregate dell’architettura dei siti web e dei dati accesso, keyword e molto altro ancora).
In parallelo abbiamo eseguito manualmente decine e decine di ricerche per analizzare i risultati della ricerca ma anche per raccogliere le combinazioni di keyword, tag e classificazioni pre-esistenti che potevano creare un valore per le nostre personas. E’ un lavoro editoriale che richiede tempo e una cognizione base dei diversi dominii di conoscenza.
Usando la logica del Patchinco (ovvero la costruzione modulare di un albero di classificazione) abbiamo iniziato a definire le logiche di ri-classificazione dell’esistente rispetto alla nuova classificazione tematica che via via prendeva forma. Queste logiche ci hanno consentito di implementare un primo modulo in Drupal per l’acquisizione e la ri-classificazione dei dataset originariamente contenuti in CKAN. L’organizzazione dei temi è stato il risultato degli incontri con AgID ma anche una mappatura delle diverse tassonomie utilizzate a livello Europeo dai vari portali open data.
Ora per quanto parziale è emersa una nuova logica di ri-classificazione dei dati che mette insieme diversi criteri di accesso alle informazioni.
I focus
I focus hanno l’obiettivo di interessare delle comunità trasversali di utenti che accedono al sito con interessi specifici. Nel CMS rappresentano degli aggregati di dataset, di news (e presto anche di app) che possono interessare il target. Ne abbiamo concepiti quattro in prima battuta e aggiunti altri due in corsa. I primi quattro da cui eravamo partiti sono:
Smart City (è un tema importante per lo sviluppo economico e l’interesse è in crescita),
Dati Geografici (si tratta di un sotto-insieme molto specifico di dataset che hanno un riferimento diretto con il territorio e che si rivolgono tradizionalmente ad una platea di utenti spesso composta da professionisti),
Data Journalism (i dati statistici aiutano a raccontare le storie e a produrre informazione basata su fatti concreti)
Agenda Open Data (forse il focus più importante di tutti che raccoglie la lista dei dataset identificati come fondamentali dall’agenda digitale del Paese dal 2013 ad oggi – l’obiettivo è quello di esporre in modo chiaro ai cittadini quali dataset sono prioritari e quali di questi sono realmente disponibili).
I due aggiunti in seguito sono stati:
Data 4 All (un progetto presentato all’UNICEF che raccoglie alcuni dei progetti Open Data di maggior risalto al momento ovvero Open Expo, Italia Sicura e Soldi Pubblici)
Occupazione & Lavoro (la sintesi delle informazioni relative ai livelli occupazionali)
Al momento sono in linea tre focus e speriamo di introdurre anche gli altri tre nei prossimi mesi (questo ovviamente dipenderà dalle valutazioni congiunte di AgID e Formez).
Perché DKAN al posto di Drupal + CKAN
Effettivamente non è scontata come scelta e vale la pena entrare nel merito. In passato abbiamo lavorato su CKAN e la sua endemica diffusione ne rappresenta il principale punto di forza.
Quando fu concepito originariamente da Dr Rufus Pollock e l’OKFN l’obiettivo era quello di creare uno strumento semplice per pubblicare cataloghi di dataset. Ora le ambizioni di un sito come dati.gov.it come anche quelli di altri cataloghi regionali e/o di settore sono legate al ri-uso dei dati e più in generale alla divulgazione di quanto sia possibile fare con questi dati. Si tratta di favorire l’impiego da parte di tutti dei dati per creare nuove opportunità sul territorio integrando le competenze di tecnici e meno tecnici.
Utilizzare un CMS significa poter trattare i dataset come qualunque altra tipologia di contenuto e abbinarlo ad articoli di approfondimento, applicazioni e molto altro ancora. Analizzando la navigazione dei portali realizzati con CKAN abbinato ad un CMS (Drupal o WordPress) è facile notare come sistemi diversi di navigazione si sovrappongano perché appartenenti a piattaforme diverse. Si veda ad esempio il portale (molto ben realizzato per altro) della Regione Lazio o anche la stessa precedente versione didati.gov.it – i dati sono accessibili e consultabili con una logica specifica che è di fatto vincolata da CKAN mentre gli altri contenuti rimangono “sospesi” in un’alberatura che è definita nel CMS.
Un CMS consente inoltre un’espressività maggiore in termini di organizzazione dell’architettura delle informazioni e facilità di creazione della presentazione – ma anche una crescita delle funzionalità più organica e meno dispendiosa (nel caso di Drupal legata ai 300+ moduli presenti per questo sistema).
Ora inoltre si trattava di passare da una piattaforma con un harvesting automatico che utilizzava un sistema di crawling per raccogliere e classificare i dati ad un workflow di pubblicazione e gestione centralmente organizzato da AgID e Formez integrable con l’indice della Pubblica Amministrazione. Avere quindi la possibilità di creare dei workflow di acquisizione più strutturati rispetto a quanto offerto da CKAN era un requisito da considerare per lo sviluppo futuro del sistema.
Last but not least – un comune che ha un budget limitato e usa un WCM open source come Drupal (in Italia sono tantissimi) perché dovrebbe installare una nuova piattaforma e formare il personale?
Continua … e nel prossimo articolo parleremo delle tanto attese API, della treemap utilizzata sulla homepage, delle contribuzioni open source e di altri approfondimenti implementativi.
La foto di copertina è di Justin Grimes , CC BY-SA 2.0
Il sito dati.gov.it è stato pubblicato in una prima versione il 5 Giugno 2015.
Stiracchiando quà e là questa descrizione potremmo dire che anche i prodotti dell’uomo d’azione sono a loro volta introspettivi e sociali.
Un contenuto web, anche quello con un grado di multimedialità intrinseco elevato, rimane sempre un prodotto del sottosuolo (o sottobosco o dell’uomo di pensiero). Per emergere almeno al piano terra ha bisogno dell’applicazione delle politiche adottate dai motori di ricerca. Altrimenti: nisba! E se per caso si sceglie il passaparola in vece del marketing digitale, scelta piacevole, si rimane sempre nell’area pensiero, ma debole perchè manca della struttura di classificazione usata per gli open data: dbpedia e altro, impedendo di fatto al post la necessaria visibilità.
chi scrive per non essere letto? chi racconta una storia senza voler essere ascoltato?
WordLift 3.0 sviluppato da Insideout10 è un editor semantico che aiuta chi scrive suggerendo relazioni, descrizioni e approfondimenti a seconda del contenuto da pubblicare, e fa tutto questo senza dimenticare di associare i metadati che identificano univocamente il post e lo rendono compatibile con la classificazione LOD, la più riconosciuta e la più diffusa nel web. L’editor semantico tratta il testo del post come fosse parte di un capitolo in un romanzo: ‘che sembra scritto per noi’, che ci fa vedere una parte di noi che non pensavamo potesse essere condivisa da altri, che inquadra come per fare un selfie al post col suo sfondo.
Il software tratta i post come un capitolo di un libro: Li inserisce in una struttura di relazioni, in un racconto; ma la storia rimane sempre dello scrittore.
Wordlift 3.0 fa vedere il contesto dove verrà pubblicato il contenuto mettendo in relazione l’archivio interno del blog o sito internet, con tutto il web, che è lo scenario di riferimento.
Chi scrive ha così un potente strumento di supporto alla scrittura: di verifica culturale e statistica, molte volte di scoperta vera e propria; ma niente serendipity se non casuale.
Terminata l’elaborazione, accettati o meno i consigli, il software associa in automatico i metadati suggeriti dalla componente dedicata alla comprensione del testo. Altri metadati possono essere inseriti manualmente, poi si pubblica.
A seconda dell’uso che se ne vuole fare, mettiamo minimale, chiamiamola classificazione tipo SEO — cioè che associa in automatico un set di metadati, è richiesto al giornalista digitale un tempo aggiuntivo alla fase di pubblicazione che non supera il paio di minuti. Per il resto dipende dalla volontà di usarlo o meno come strumento di ricerca per il design del contesto di pubblicazione.
Un bellissimo progetto avviato in questi mesi con Enel per pubblicare i dataset geo-referenziati presenti sul portale Open Data (http://data.enel.com) sulle mappe di OpenStreetMap: questa volta parliamo di…stazioni di ricarica per veicoli elettrici.




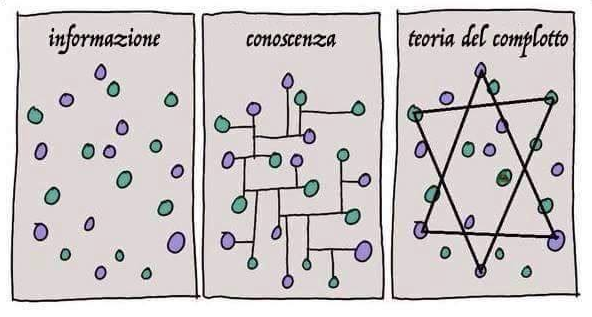 WordLIft 3.0 fa passare dall’informazione alla conoscenza evitando il complotto.
WordLIft 3.0 fa passare dall’informazione alla conoscenza evitando il complotto.

 Ma torniamo all’Oriente. Per descrivere il grado di casualità della nascita raccontano/vano:
Ma torniamo all’Oriente. Per descrivere il grado di casualità della nascita raccontano/vano: 

 Come startup che lavora in questo settore, siamo a nostra volta “clienti” della soluzione, questo costituisce un punto di vantaggio e un
Come startup che lavora in questo settore, siamo a nostra volta “clienti” della soluzione, questo costituisce un punto di vantaggio e un 



